

Why we wrote this
Building products is a challenging endeavour and we'd like to share some of our experience with the AEC community.
Context
On 10th Sept (a Thursday) last quarter, we shipped a brand new version of our ValidationHub product that enables teams to automate file naming QA/QC compliance on BIM360. The major new feature was something we'd been working towards since we first launched the product : a visual rule builder that allows customers to easily build entirely custom naming schemas without having to write any code or complex templates, it's all visual!

The launch went well and customers loved the new visual rule builder, echoing feedback from our customer research and early access testers. This would be a short blog post though if there wasn't a twist.
Crashing the app
Meanwhile, my co-founder Mark was busy crashing the newly updated app with a brand new dataset from a customer (in our dev environment of course, not impacting users). For context, Mark had been busy talking to many teams interested in using ValidationHub to automate part of their document control process and uncovering what these teams would need help with. This of course is part of our normal product development process, we spend a lot of time trying to understand where we can best help customers.
Anyway, back to this dataset. One of the things our rule builder enables is to check if a field is on a list of approved valued. For example, standards such as #ISO19650 or#BS1192 specify the document type field can only be one of the following values: DR, M2, M3, SH, etc. We already have built-in rules that cover BS1192, PAS1192 and ISO19650, so we're well aware of how many possible values could be on these pre-approved lists : usually no more than 100 unique values. As for customer datasets, nothing we'd seen so far exceeded 100.
Enter this new dataset, which had one field with a list of 22,800 approved values. That's not10x, but 200x more than anything we'd considered. It came as a CSV file and even our code editors struggled to render it, which is a telling sign. Our back-end services can handle this without issue and we even have tests for this. But on our web app, based on customer usage we'd seen, I made the assumption (I know, I know!) it's highly unlikely to have more than 100 values, meaning we never tested for such high numbers. We try hard to never make assumptions in our products, but this shows how despite deliberate efforts by the product team, some assumptions might still sneak in.
So, as Mark was copy-pasting those 23k values in, our web app was trying really hard to render a nice-looking tag for each of them and make each individual tag removable from the list. Obviously things didn't quite work: pasting the values in would make the browser non-responsive for a bit. Eventually, the app would recover but the user interface would still be slow, trying to handle that monster list.
If there's one thing to remember from this article, here it is in meme form, paraphrasing a quite famous quote from military origins:

No product plan survives contact with the customer.
So how did we tackle this ? Read on...
The fix
We obviously wanted to fix the experience for ValidationHub users as quickly as possible, so we discussed things internally and identified this as a two-in-one: it's both a performance issue with the current app and a potential feature improvement.
So, we agreed we'd have a two-stage approach:
1. fix the performance issue for the app immediately
2. enhance the app to make it easier for our customers to handle these large lists
Performance issue
If you're not interested in the technical details, feel free to skip this section, but if you're curious read on.
It's no secret that I'm (me, Radu) no JavaScript wizard, but my initial thought was that because we we're rendering those nice pill tags for each value, the front-end framework we use (VueJS) was creating, trying to keep track of and render too many reactive objects. Fortunately for us, our teammate and front-end developer Ola was already on the case, confirmed that was indeed the issue and got started on the improvements.
We needed to fix the performance issue in the live app as quickly as possible, without negatively impacting the existing app capabilities. Here's some of the changes we made and how each impacted the performance and UX.
swapped text input field for a text area field (large string input)
We originally envisioned users entering a few values at a time, so the implementation used a text field where you could enter comma-separated values that would then be parsed and rendered as pills. Even on modern browsers, input fields have performance issues with very large texts though, so pasting lots of values into the field was problematic not matter what our app did or which browser was used.
We switched to using a text area field which is designed for longer texts. This alleviates the performance issue when pasting many values but also makes the text area resizable, see the gif below.
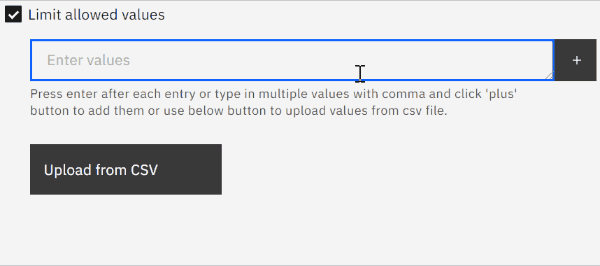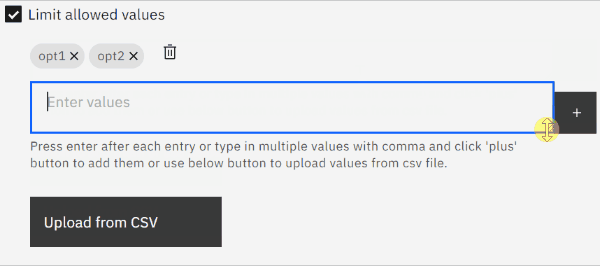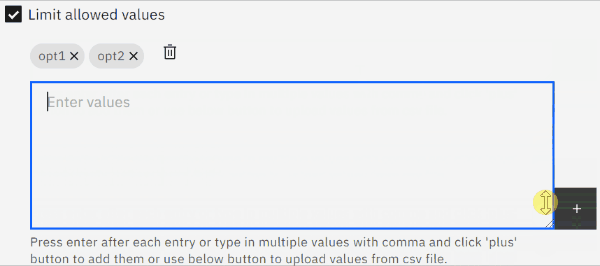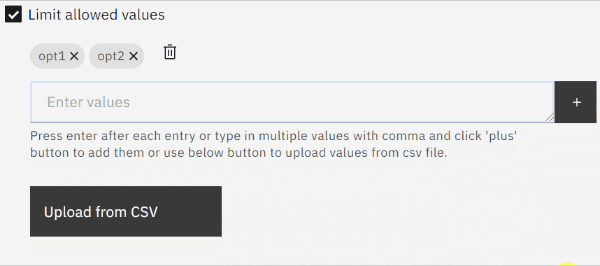
limit displayed pills to first 30 values
Due to my original assumption of how many values we'd potentially see here, we were rendering all of them on the screen. As you can imagine, that wasn't a great user experience and was also causing performance issues. So we quickly tested several design variations of how many items would be comfortably displayed and settled on 30. We also added a warning text for users letting them know the list is only partially displayed.
Here's what this looks like today:

Display all values in a modal without using pills
Because we're now limiting how many items are shown, we needed to enable users to view the entire list as they were able to before. We added a "See all values" button that displays the list in a modal. The technical aspects to note here are that the list is a simple comma-separated string, so we're not creating thousands of DOM elements or using fancy pills that are reactive.

This makes the list super-fast to scroll and searchable with the browser's built-in Ctrl+F mechanism.

We deployed these changes to our testing environment, ran tests and deployed to production once everything was 👍.
UX to handle large lists
Now that a fix for the performance issues with large lists was deployed, we turned our attention to the second part of the mitigation plan, the app's shortcomings for users that need to manage naming schemas with long lists of allowed values. We went back to our customers and asked how they managed these lists in their own environment and the majority that responded pointed to Excel.
In essence, this was an opportunity to make it easier to input allowed values for customers who already had this list somewhere else. We settled on a CSV file upload as it was the most compatible with different data sources, worked up the feature requirements and got to work again.
The intervention itself was on purpose rather minimal: the addition of an "Upload from CSV" button. There's no separate file management area and once a file is selected and uploaded, the parsed list of values is merged with the existing list of values the user might have already entered into the text area. Having these two input methods combine into a single list meant the UX for existing users was unaltered and the CSV upload addition was just that: a helpful addition.
Here's what uploading that CSV file looks like for our customers, it's seamless and instantaneous:


Conclusion
We launched a major new feature, found some new performance issues, shipped a fix and then anew UX improvement feature, all in less than 24 hours from launch - makes me very proud of our product team! None of this would be possible without them and of course our passionate customers!
If you're curious for more behind-the-scenes, let us know on social channels.
Or join us - our development team is growing!
KOPE: optimisation for everyone
Lets automate DfMA: Part 4 - KOPE
Subscribe to Our Newsletter
